一、引言
在上一篇文章中,我们探讨了weak的底层实现原理,其中涉及到一个概念——DenseMap,包括后面要讲到的NSObject的引用计数原理,都离不开DenseMap,因此,在开始后面的篇章之前,有必要了解DenseMap的底层实现和原理。
DenseMap实际上是一个基于二次探查法的哈希表,在runtime的应用非常广泛(用作object的引用计数表等)。其具体实现可以在objc4-750的llvm-DenseMap.h文件中找到。本篇我们对DenseMap从内存结构和Hash实现两个方面进行简单的分析。
二、DenseMap的内存结构
先看看DenseMap的内部结构:
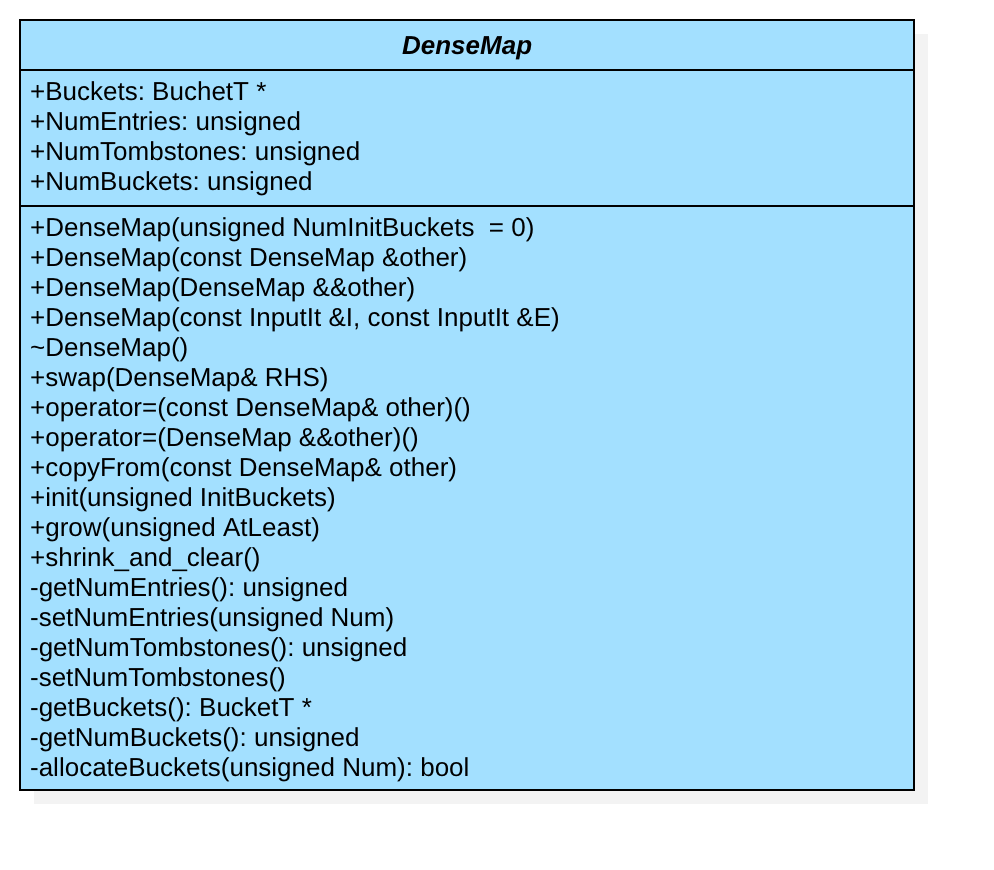
开始下文之前,先了解llvm-DenseMap.h中的一些类型定义:
- BucketT
BucketT为存储key-value的Hash桶,在DenseMapBase中定义:
1 | typedef std::pair<KeyT, ValueT> BucketT; |
这里使用了C++标准库中的pair模板结构体(std::pair),它的作用是将两个数据(可以是同一类型或不同类型)组合成一个数据。
1 | struct _PairT { |
first表示pair中的第一个元素(在BucketT中即为key),second表示pair中的第二个元素(在BucketT中即为value)。这个概念在后面还会用到。DenseMap中直接使用了基类中的BucketT的定义:
1 | typedef typename BaseT::BucketT BucketT; |
- BaseT
BaseT定义为基类DenseMapBase:
1 | typedef DenseMapBase<DenseMap, KeyT, ValueT, KeyInfoT, ZeroValuesArePurgeable> BaseT; |
DenseMap继承自DenseMapBase,DenseMapBase中包含了DenseMap的Hash逻辑实现,在下节中详细讲。DenseMap中有四个成员变量:
BucketT *BucketsHash桶的首地址,桶中存储的是std::pair<KeyT, ValueT>键值对unsigned NumEntries存储的数据数目unsigned NumTombstonesTombstone个数,在解决Hash冲突时要用到该数据unsigned NumBucketsHash桶的数目
2.1 init
DenseMap初始化涉及到三个函数:init, allocateBuckets, initEmpty。分别看下这三个函数
1 | void init(unsigned InitBuckets) { |
init函数首先调用allocateBuckets根据初始Bucket的个数分配内存空间(使用operator new分配内存),如果初始桶的个数为0,设置NumEntries和NumTombstones为0;否则,调用DenseMapBase中的initEmpty对这些空桶进行初始化。initEmpty函数中对NumEntries和NumTombstones的值进行初始化,然后判断Bucket的数量是否为2的次幂,DenseMap要求Hash表的容量(Bucket桶的数量)必须是2的次幂。然后遍历所有的Buckets,初始化其key为EmptyKey。关于empty key的计算,放到第三节中讲。
2.2 Hash桶的增长和缩减
- Hash表扩容
1 | void grow(unsigned AtLeast) { |
这里的Hash表的增长与上篇文章中存储weak变量的散列表的增长方式基本相同:是先分配一块新的内存,将老的内存数据复制过来,用这种方法实现Hash表的动态增长。在复制老数据时,跳过那些key为EmptyKey和TombstoneKey的元素:
1 | if (!KeyInfoT::isEqual(B->first, EmptyKey) && |
那么什么时候调用grow函数对Hash表进行扩容呢?
1 | if (NewNumEntries * 4 >= NumBuckets * 3) |
从代码可以看出:
- 当前Hash表中的元素数量大于容量的3/4时,对Hash表进行扩容,容量增加至少1倍(注意,实际增加的表容量大小必须为2的次幂)。以保证散列表的装填因子(
load factor)维持在0.75; - Hash表中的空余槽位(这里表现为空的Bucket)小于容量的1/8时(此时,Hash表中的大部分元素被填充为
TombStone),维持表的原有容量,并进行rehash操作。
- Hash表收缩
1 | void compact() |
- 如果当前Hash表中的没有元素,执行清理操作
shrink_and_clear; - 如果当前Hash表中的元素数量小于容量的1/16而且当前表的容量大于
MIN_COMPACT,收缩表的容量至表中当前元素数量的2倍。
shrink_and_clear执行Hash表的清理工作,主要是重新分配一块内存,内存的大小为MAX(MIN_BUCKETS, 2^ceil(log(OldNumEntries))),其中log以2为底,OldNumEntries是执行清理之前的Hash表中元素的数目。分配完内存之后进行初始化,释放掉原有的内存。
1 | void shrink_and_clear() |
问题:什么时候收缩Hash表呢?
当NSObject对象释放的时候,会调用对象的函数:obj->clearDeallocating()(具体细节本文暂不分析),最终会调用DenseMap的erase函数,执行Hash表的清理和收缩操作:
1 | void erase(iterator I) |
对象释放之后,它在Hash表中对应的元素并不会马上被删除,而是将其对应的key设置为TombStone Key,表示该对象已经销毁,然后等到合适的时机,调用grow函数调整表的容量。
三、DenseMap的Hash实现
DenseMap的Hash实现逻辑都封装在其基类DenseMapBase中,Hash的实现离不开key的计算,包括上一节中提到的Empty Key和TombStone Key等,这些逻辑都是在DenseMapInfo<>模板类中实现。DenseMapInfo提供了针对runtime需要用到的类型(指针、DisguisedPtr、cstring、char、unsigned int、unsigned long、unsigned long long、int、long、long long、std::pair)的key的实现。
基本上,Empty Key是该类型所能表示的最大值,比如对于unsigned long类型,它的Empty Key为~0UL,TombStone Key为Empty Key - 1。这里就不一一列出了,感兴趣的同学可以查看llvm-DenseMapInfo.h文件。
下面详细介绍一下Hash Key的计算。
3.1 Hash Key的计算
先看下不同类型的getHashValue实现:
1 | static unsigned getHashValue(const T *PtrVal) { return ptr_hash((uintptr_t)PtrVal); } |
- 对于指针类型,使用
ptr_hash计算其hash key,详情请看上一篇文章 - 对于string类型,使用
_objc_strhash计算其hash key - 对于char/int/long/long long等类型,采用乘法作为哈希函数,这里的哈希函数为:hash(k) = 37 * k,它们的Hash Seed都选择了37。
在设计哈希函数时,通常选择一个数(记做A)来改变哈希函数的状态值,这个数叫做种子(Hash Seed)。根据哈希表的特性,哈希函数计算出来的key分布越均匀,哈希冲突越少,哈希表的性能就越高,因此通过哈希函数计算得到的哈希值一定要在统计学上具有更高的熵,也就是尽量均匀分布。如果我们传入哈希函数的参数是完全随机分布的,那么随便选一个seed进行计算得到的结果也一定是完全随机的,当然这只是理想的情况。实际应用中,我们给哈希函数的入参是具有某种规律的,比如连续的内存地址、具有某种分布规律的整数等等。这时我们寻找的seed就要求能尽量避免哈希冲突的发生。基于这种目的,设计哈希函数时通常选取素数作为seed。
说实话,看到Val * 37U时有些诧异,本以为Apple会设计一个相当复杂晦涩的Hash函数,结果,so simple。。。猜测也许是runtime中针对整型的hash计算使用的很少,就用了一个简单的哈希函数,虽然会偶尔发生碰撞,但是也在可接受的范围内。借用网上的一段话:
I have also worked on the hashing for integers and my first test was trying to measure difference in performance when putting the worst hash function you can think of for integers : hash(k) = 0. It turns out that the difference I measured is below 0.5 %, which is below the noise of repeating experience. So, with my benchmark (compiling a .cpp file with clang with -O3), the quality of the hash for integers doe not matter at all. It seems that the usage of integers as keys is very low.
3.2 Hash表的存取
既然是散列表,那么碰撞/冲突是不可避免的,DenseMap是怎么解决冲突和对Hash桶进行存取的呢?
3.2.1 碰撞解决
DenseMap哈希表采用开放寻址——二次探测法(quadratic probe)解决碰撞。find和insert都会调用LookupBucketFor寻找合适的槽位(slot)。看下LookupBucketFor中有关二次探测的代码:
1 | unsigned BucketNo = getHashValue(Val) & (NumBuckets - 1); |
寻找合适的Bucket以及二次探测的过程如下:
- 调用hash函数通过传入的参数
Val计算出key,并使用key & (所有桶数量 - 1)运算得到Bucket ID,赋值给BucketNo,这个运算相当于取余,保证计算的ID在Buckets范围内; - 初始化探查计数
ProbeAmt为1; - 如果
Buckets[BucketNo]的key与入参Val相同,说明找到对应的Bucket,记录该值(FoundBucket = ThisBucket),返回true; - 如果
Buckets[BucketNo]的key与Empty Key相同,说明找到了一个空桶,然后判断在找到这个空桶之前,是否找到过TombStone Bucket,如果找到过,记录这个TombStone Bucket,返回false; - 进行二次探查并与
NumBuckets-1去余,得到BucketNo,转到3继续执行,直到返回或者函数出错。
这里二次探测的关键代码是:
1 | BucketNo += ProbeAmt++; |
如果ProbAmt没有自增运算,那么就是线性探测(上一篇文章中,存储weak变量散列表的探测方法就是线性探测)
3.2.2 插入
插入时调用insert函数:
1 | std::pair<iterator, bool> insert(const std::pair<KeyT, ValueT> &KV) |
插入时首先调用LookupBucketFor函数寻找合适的插入位置,如果Bucket已经存在,直接返回false,并且不更新Bucket。否则调用InsertIntoBucket创建新的Bucket并插入到散列表中。InsertIntoBucket首先调用InsertIntoBucketImpl寻找合适的插入位置,并返回一个空Bucket或者Tombstone Bucket,这个过程中,如果哈希表中空桶的数量不足(装载因子大于等于0.75时),对哈希表进行扩容。
1 | BucketT *InsertIntoBucketImpl(const KeyT &Key, BucketT *TheBucket) |
InsertIntoBucketImpl的流程如下:
- 判断插入新的元素后哈希表的装载因子(
NewNumEntries/NumBuckets)是否>=0.75,如果是,为了维持低碰撞率,需要对哈希表进行扩容,增加Bucket的数量,然后重新计算插入位置; - 如果装载因子
<0.75,但是表中空桶数量过少(EmptyBuckets / NumBuckets <= 1/8), 说明表中的Tombstone Bucket太多,而Tombstone可能会导致死循环(比如,当哈希表中所有桶都为Tombstone Bucket时,调用LookupBucketFor中二次探查的while循环永远不会结束,具体原因可看上文代码),这时要对哈希表进行rehash操作,但是并不增加桶的数量,然后重新计算插入位置; - 增加
NumEntries,如果插入位置为Tombstone Bucket,则相应地减少Tombstone Bucket的数量
3.2.2 删除
删除操作由erase函数实现。
1 | bool erase(const KeyT &Val) |
这个函数没什么难点,设置置Bucket的key为Tombstone key,这里多讲一句,之所以不直接删除Bucket,而是将其标识为Tombstone,原因就是为了不影响查找过程中二次探查的结果。
四、总结
DenseMap本质上是基于开放寻址二次探查法的HashMap,表中的元素是key-value pair(这些pair被封装为BucketT,称作“桶”),桶有三类:1、存有值的桶;2、空桶;3、标记为Tombstone的桶。DenseMap针对不同的数据类型设计了不同的Hash函数,比如:指针类型的Hash函数为ptr_hash,基本数据类型的Hash函数为hash(k) = 37 * k。
有关LLVM中DenseMap的更多介绍,可以看下这两篇文章: