一、引言
1 | // 1. |
相信大家对上述代码不陌生,weak修饰对象表示对该对象的弱引用,弱引用不会增加对象的引用计数,并且在所指向的对象被释放之后,weak指针会被设置的为nil,同时避免了”野指针(或者suspend pointer)”的问题。在使用代理模式或者block时,为了避免引起retain cycle而导致内存泄露,我们通常使用weak关键字来打破循环引用链。
之前只是单纯的知道使用weak,但是对于更深层的原理,正文开始前,先提出三个问题:
- weak为什么不会增加对象的引用计数
- weak对象存储在哪里
- 对象释放时其weak指针如何自动设置为nil
现在带着这些问题来一探究竟。本系列文章使用的源码:objc4-750
二、存储结构分析
先看下测试代码:
1 | NSObject *obj = [NSObject new]; |
在__weak出断点并单步运行,发现它实际上调用了objc_initWeak函数。
在runtime源码中找到相关函数的实现如下:
1 | id objc_initWeak(id *location, id newObj) |
该函数有两个入参:
- location: __weak指针的地址
- newObj: 需要进行弱引用的对象的指针
实际上该函数只是一个更深层函数的入口,在调用更深层函数之前做了一些判断,如果newObj已经被释放,同时置weak对象指针为空,并返回nil。否则调用storeWeak函数进行下一步处理。
注意,从函数的注释中可以看出,objc_initWeak不是线程安全的,因此在设置或修改weak对象时,注意避免一些因多线程引发的问题。
2.1 objc_storeWeak函数
先看下函数实现:
1 | enum CrashIfDeallocating { |
首先定义了一个模板参数,包含了三个参数:
- HaveOld true: 变量已经有值,需要先清理;false: 变量没有值,无需清理
- HaveNew true: 有一个新的值需要分配给变量,当前值可能为nil;false: 没有需要分配的新值
- CrashIfDeallocating true: 当newObj正在释放或者newObj不支持弱引用时,进程停止;false: 进程不停止,存储nil代替。
然后从SideTables中取出相应的oldTable和newTable。
1 | static StripedMap<SideTable>& SideTables() { |
在SideTables()函数中使用了C++的强制类型转换符:reinterpret_cast:
1 | // 这里的type_id 必须是一个指针、引用、算术类型、函数指针或者成员指针 |
它把expression转换成type_id类型,但是不做任何类型检查和转换,其结果只是简单地从一个指针到另一个指针的值的二进制copy,通常用于底层代码。
StripedMap是一个模板类(Template Class),通过传入类(结构体)参数,会动态修改在该类中的一个array成员存储的元素类型,并且其中提供了一个针对于地址的hash算法,用作存储key。可以说,StripedMap提供了一套拥有将地址作为key的hash table解决方案,而且该方案采用了模板类,是拥有泛型性的。
1 | template<typename T> |
看下SideTable的内部结构:
1 | struct SideTable { |
SideTable结构体中定义了如下内容:
- spinlock_t slock 自旋锁,用来保证多线程下的原子操作
- RefcountMap refcnts 引用计数表,Hash表
- weak_table_t weak_table 弱引用表,Hash表
- 构造函数 其中包含了weak_table的初始化代码
- 析构函数
- 加锁、解锁等:lock()/unlock()
- 对oldTable和newTable进行加锁、解锁操作的函数:lockTwo/unlockTwo
RefcountMap是runtime中用于存储引用计数的hash表,它使用DenseMap数据结构来实现:
1 | typedef objc::DenseMap<DisguisedPtr<objc_object>,size_t,true> RefcountMap; |
对DenseMap的讨论超出了本篇的范围,这里我们只需要知道DenseMap是在llvm中定义并广泛使用的一种数据结构,它本身的实现是一个基于Quadratic probing(二次探查)的散列表,键值对本身是std::pair<KeyT, ValueT>。想看相关源码的同学可以戳这里:llvm-Densemap.h
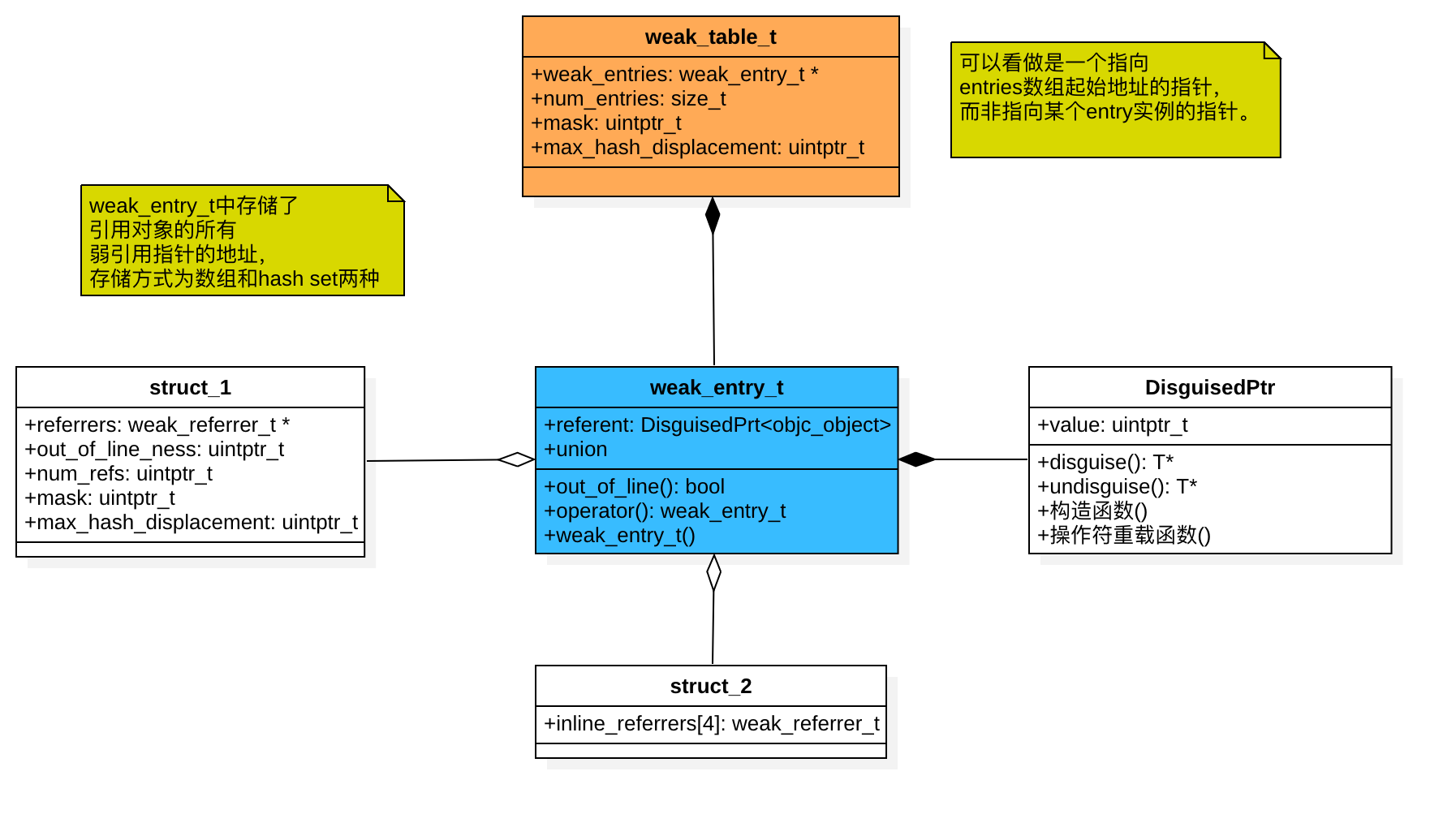
2.2 weak_table_t
全局的弱引用散列表,存储了所有weak变量(weak变量实际存储在weak_entry_t中,与对象相关联,下文详细介绍),先看下它的组成:
1 | struct weak_table_t { |
- weak_entry_t *weak_entries 指向了所有对象的所有weak变量存储区域的入口
- size_t num_entries 存储空间大小
- uintptr_t mask
- uintptr_t max_hash_displacement 对应key的值在hash表中的最大偏移值
weak_table_t使用hash表存储所有的weak变量,hash key是需要进行weak引用的对象,value是对象对应的entry(weak_entry_t结构体),entry中使用数组或hash表的方式存储了与对象相关的所有weak变量的指针。
看下weak_entry_t:
1 | struct weak_entry_t { |
逐个成员变量看:
DisguisedPtr<objc_object> referent封装为DisguisedPtr类型的对象指针referent,该指针即指向需要进行弱引用的对象,封装的目的是为了解决weak hash表可能导致的内存泄露的问题。union联合体 这里首先要明白union的一些概念,union的成员变量都是在同一地址存放的,使成员变量相互覆盖,共同占用同一段内存。union具有以下特点:1、
union同一个内存段可以用来存放多种不同类型的成员,但是同一时刻只有一个成员起作用
2、union中起作用的是最后一个存放的成员,在存入一个新成员后,原有的变量就会失去作用
3、union中所有成员的起始地址相同
4、union占用的内存长度等于最长的成员的内存长度,而struct的内存长度为其中所有成员变量占用的内存之和这里的
union中定义了两个struct成员变量,这两个struct用于不同情形下的weak弱引用指针的存储。
当
out_of_line_ness != REFERRERS_OUT_OF_LINE时,weak_entry_t中存储二维指针的区域是一个名称为inline_referrers的数组,该数组中的元素为weak指针的指针。当
out_of_line_ness == REFERRERS_OUT_OF_LINE时,weak_entry_t中存储weak二维指针的区域为一块特定的内存区域,referrers指向这块内存区域的起始地址,在这块内存的存取函数中定义了相关的hash key函数以及冲突解决策略等,将这块内存区域构造成一个hash set使用(后文再详细展开)。
// out_of_line_ness field overlaps with the low two bits of inline_referrers[1].
// inline_referrers[1] is a DisguisedPtr of a pointer-aligned address.
// The low two bits of a pointer-aligned DisguisedPtr will always be 0b00
// (disguised nil or 0x80..00) or 0b11 (any other address).
// Therefore out_of_line_ness == 0b10 is used to mark the out-of-line state.
out_of_line_ness变量与inline_referrers[1]的最低两位重叠(inline_referrers[1]也是一个封装为DisguisedPtr类型的指针),在源码的注释中也说了,out_of_line_ness和inline_referrers[1]的最低2位重合,在64位系统下,out_of_line_ness和num_refs一共占用64bit,由于此时内存结构刚好对齐(out_of_line_ness和num_refs的长度加起来刚好与inline_referrers[1]的长度相同),所以下一个元素mask的内存地址刚好换行。
weak_referrer_t是一个封装为DisguisedPtr的objc_object类型的二维指针(objc_object **)
1 | typedef objc_object ** weak_referrer_t |
看下weak_entry_t的构造函数:
1 | weak_entry_t(objc_object *newReferent, objc_object **newReferrer) |
在创建weak_entry_t实例时,默认使用inline_referrers数组的方式来存储weak指针的指针,并把其余位上的数据清空。至此可以做出如下推断:当对象的weak变量的个数小于WEAK_INLINE_COUNT时,weak_entry_t中使用简单的inline数组(即:inline_referrers)方式来存储该对象的这些weak变量的指针,当inline_referrers数组装满之后,out_of_line_ness被设置为REFERRERS_OUT_OF_LINE,这时如果该对象有更多的weak变量,使用out_of_inline的方式存储(存储于hash表)。这么做也是基于性能的考虑,很明显当对象有大量的weak变量时,hash表的存取效率是优于数组的。
2.5 小结
通过上文的分析,可以看出对象的weak变量的存储结构,首先是两个结构体:weak_tale_t和weak_entry_t,它们中分别定义了一个hash表,其中weak_tale_t存储多个weak_entry_t,以hash表的形式存取,weak_entry_t存储某个对象的所有弱引用变量的指针(二维指针的形式),它里面也有一个hash表(当弱引用变量的数量<=4时,以数组的方式存取)。
三、部分细节分析
既然上文说了weak变量都是以hash表的形式存取,自然而然地能想到这些问题:
- hash表是怎么实现的
- hash函数是怎样的
- 怎样解决hash冲突
- hash表是如何存取、删除的
带着这些问题,开始下面的分析
3.1 hash key计算
看下objc-weak.mm文件中有两个hash函数:
1 | static inline uintptr_t hash_pointer(objc_object *key) { |
这两个hash函数根据对象的指针或对象指针的指针,通过ptr_hash函数生成key,这个key就是存取hash表的关键。
hash_pointer函数对应weak_table_t中的hash表(即weak_entries),根据被弱引用对象的地址生成keyw_hash_pointer函数对应weak_entry_t中的out_of_line时的referrershash表,根据对象的weak变量的指针生成key
看下哈希函数ptr_hash:
1 | static inline uint32_t ptr_hash(uint64_t key) |
ptr_hash基于一种Fash Hash算法,该算法一定程度地牺牲hash准确度以保证hash的速度,这个哈希函数相当的简洁,但却行之有效。至于为什么key >> 4,猜测是malloc分配内存后的指针都有16字节偏移的原因,在这种情形下key >> 4能够达到很低的碰撞率,具体的讨论可以看这里:[llvm-dev] Default hashing function for integers (DenseMapInfo.h)。有关malloc指针的16字节偏移的问题没有深入思考过,等以后有时间再进行吧。
3.2 weak_entry_t插入
grow_refs_and_insert函数:
1 | __attribute__((noinline, used)) |
向weak_entry_t中hash表新增数据时,首先创建一个新的存储空间(大小为old_size * 2),然后将所有的老数据复制到新的空间中,然后再将新的数据插入到新的空间中,最后释放老的存储空间。为什么要这么做呢?我们知道C数组的长度在创建的时候就固定了的,为了能够动态地向数组中添加新元素,就需要不断地申请新的内存空间(并且要求是连续的内存地址),这样就必须把老的数据复制到新申请的内存空间中,然后再加入新增的数据,最后释放掉原内存空间。同时,为了避免频繁地申请新的内存空间和复制数据,将新内存空间大小的增长设置为原来的2倍。
grow_refs_and_insert函数使用append_referrer对entry进行数据插入操作。
1 | static void append_referrer(weak_entry_t *entry, objc_object **new_referrer) |
append_referrer函数的流程比较简单:
- 插入新值时先判断当前entry是否out_of_line,如果没有,使用inline的方式将新值存储到
inline_referrers数组中,如果inline存储方式失败,转为out_of_line的方式,分配一块大小为WEAK_INLINE_COUNT的内存空间,将起始地址赋值给new_referrers; - 然后判断当前entry中的弱引用数量,如果超过了当前存储空间的3/4,对存储空间进行扩容。扩容的目的是避免hash表的装填因子过大,由于这里采用线性探测再散列法解决hash冲突,当装填因子非常接近于1时,线性探测类似于顺序查找,其性能相当于数组遍历,降低了hash表的存取性能;
- 最后是将新元素插入hash表,使用线性探测再散列找到可以插入的位置,插入新值并将
num_refs加1。
细心的同学可能注意到了,在计算key和线性探测的过程中有这样两句代码:
1 | size_t begin = w_hash_pointer(new_referrer) & (entry->mask); |
为何key和index的值要跟entry->mask相与呢?我们知道,entry->mask存储了referrers数组的大小,进行“与”操作后,所有超过referrers数组边界的二进制位都被置为0,避免了可能出现的数组越界的问题。
既然有插入操作,那么就有对应的删除操作:remove_referrer函数,这个函数与append_referrer的流程基本相同,不同的是它是找到hash表中相应的位置并将其值置空。这里就不详细分析了。
3.3 weak_table_t插入
weak_table_t的插入涉及到了插入、hash表的扩容等操作,相关的函数有:
weak_entry_insertweak_grow_maybeweak_resize
3.3.1 weak_entry_insert函数
1 | static void weak_entry_insert(weak_table_t *weak_table, weak_entry_t *new_entry) |
可以看到weak_entry_insert函数的流程与上文的append_referrer函数相似,只是省略了inline方式存储的尝试,说明weak_table_t中默认使用hash表的方式存储所有的entries实例。
3.3.2 weak_grow_maybe函数
1 | static void weak_grow_maybe(weak_table_t *weak_table) |
weak_grow_maybe函数负责weak_table_t hash表的扩容,与weak_entry_t的策略相同:在hash表中存储的值数量大于hash表容量的3/4时,调用weak_resize函数将hash表扩容到之前容量的2倍。看下weak_resize函数:
1 | static void weak_resize(weak_table_t *weak_table, size_t new_size) |
与weak_entry_t的策略相似,不同的是weak_resize只将老数据移动到新的内存空间中,插入新数据的操作又交给了weak_entry_insert函数。
3.4 weak_table_t删除元素
1 | static void weak_entry_remove(weak_table_t *weak_table, weak_entry_t *entry) |
先判断entry的存储方式是否out_of_line,如果是,直接释放掉referrers内存空间,然后调用sizeof(*entry)获取当前entry占用的内存空间大小,将这块内存全部置0,然后将num_entries减1,最后调用weak_compact_maybe函数缩小hash表的容量至当前容量的 1/8。只有同时满足以下两个条件时才收缩表的容量:1、当前表容量>=1024;2、当前表中entry的数量<=表容量的1/16。weak_compact_maybe的源码这里就不贴出来了。
3.5 对象与weak变量的绑定、解绑等
通过前文的分析,weak_table_t存储了与某个对象关联的所有弱引用entry(weak_entry_t),这种结构类似于键值对,那么这种对象-entry的键值对是如何创建并添加到weak_table_t中的,又是如何删除的呢?
3.5.1 weak_register_no_lock
weak_register_no_lock函数负责注册一个新的对象-entry键值对,如果新的对象不存在则去创建一个新的entry并将其与该对象绑定。这里只贴出关键代码:
1 | id weak_register_no_lock(weak_table_t *weak_table, id referent_id, |
weak_register_no_lock函数做的事情主要有:
- 判断对象是否可用、是否
TaggedPointer对象,如果对象不可用或者是TaggedPointer对象,直接返回被引用的对象自身。 - 确保需要进行弱引用的对象是可用的(没有释放或没有正在释放等)。
- 如果当前被引用的对象已存在对应的entry,调用
append_referrer将弱引用指针添加到entry中。如果不存在,调用weak_entry_t的构造函数创建一个新的entry并与当前对象绑定,然后调用weak_grow_maybe对当前weak_table_t的hash表进行扩容(如果需要)。最后调用weak_entry_insert函数将新的entry插入到weak_table_t的hash表中。
3.5.2 weak_unregister_no_lock
有绑定操作就有与之对应的解绑操作,该函数的流程就不具体说了,看注释。
1 | void |
四、 结语
行文比较乱,这里自上而下简单总结一下,主要是两个结构体:
weak_table_t使用hash表的形式存储多个weak_entry_t实例(entry),并且hash表会根据entry的数量动态调整hash表的容量weak_entry_t使用数组和hash表的形式存储与弱引用对象相关的所有弱引用变量(二维指针)
回到开篇提出的三个问题:
- weak为什么不会增加对象的引用计数
我们知道,引用计数的增加离不开retain操作,而在storeWeak函数中并没有调用任何retain操作,当然也就不会使对象的引用计数增加了。对比下objc_storeStrong(对象的强引用最终调用objc_storeStrong函数):
1 | void |
- weak变量存储在哪里
看上面的总结。
- 对象释放时其weak指针如何自动设置为nil
对象释放时,runtime会调用相应的dealloc函数,而dealloc函数中会调用相应的weak指针置空函数:weak_clear_no_lock将与该对象相关的所有weak指针全部设置为nil,详情看代码注释。
1 | void weak_clear_no_lock(weak_table_t *weak_table, id referent_id) |