一、前言
前段时间接到了一个页面优化任务,一个选座的页面,要求峰值支持100*100个座位,并提高页面滑动的流畅度、内存占用率和加载速度等指标
前前后后做了一个月左右的时间,这里总结一下优化经验以供参考。
二、分析问题
1、该页面的问题所在
之前该页面的是由一系列UIButton结合drawRect实现,在从服务器拉取到数据后,计算出每个座位的frame并在相应的位置创建一个button代表该座位,所有座位加载完成后在左上角显示整体座位的缩略图。
这个过程有以下问题:
- 所有的操作都是在主线程进行,当座位较少时用户体验还好,但是当座位数增加到100*100个后,用户进入该页面后要卡住3~4s才能进行操作(在iPhone 5s上测试),用户体验较差;
- 大量的UIButton对象的创建,加重了CPU的负担并增加了内存消耗,当内存紧张时App容易被系统杀掉;而且大量的纹理渲染和视图混合等也加重了GPU的负担,造成滑动时掉帧。
- 使用snapshotViewAfterScreenUpdates创建缩略图,当座位图足够大时,很有可能超过GPU的最大纹理尺寸(参考:各机型的最大纹理尺寸),此时使用snapshotViewAfterScreenUpdates只能获取到一个空白的视图(具体原因待深究)。
2、着手解决问题
分析了问题之后,可以从以下几个方面对页面进行优化:
- 减少视图层级和对象的创建
- 尽量将绘制任务放到后台线程中执行
- 如果必须在主线程中执行,将任务分散到主线程RunLoop的各个空闲状态中执行,以保证页面的流畅
三、准备知识
1、如何将像素显示到屏幕上
首先看一张图片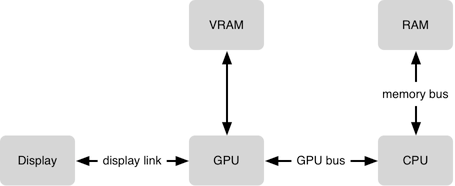
这张图片简单描述了CPU与GPU的协同工作流程:CPU将计算并绘制好的内容通过总线提交给GPU,GPU对这些内容进行渲染(GPU 需要将每一个 frame 的纹理(位图)合成在一起(一秒60次))并由视频控制器将渲染结果显示到屏幕上。虽然GPU的浮点运算非常高效,但是在1/60s(大约16.7ms)时间内能执行的操作也很有限,因此为了保证60FPS的帧率,尽量不要将复杂的渲染任务提交给GPU。
2、CPU参与的任务
对象的创建、销毁和属性调整
优化时尽量使用轻量级的对象,比如用CALyer代替UIView;如果对象的创建不涉及UI操作,尽量放到后台线程中执行;使用懒加载,推迟对象的创建时间;使用Storyboard创建视图对象时,消耗的资源比通过代码直接创建视图要大的多,因此,尽量使用代码创建视图对象。AutoLayout
大部分情况下AutoLayout能很好的提升开发效率,但是对于复杂视图来说常常会产生严重的性能问题。随着视图数量的增长,AutoLayout 带来的 CPU 消耗会呈指数级上升(http://pilky.me/36/)。如果你不想手动调整 frame 等属性,你可以用一些工具方法替代(比如常见的 left/right/top/bottom/width/height 快捷属性),或者使用 ComponentKit、AsyncDisplayKit 等框架。视图的布局计算
可以在后台线程中计算视图的布局并进行缓存。所有视图的调整最终会落到UIView.bounds/frame/center等属性上面,上文说过,对象的属性调整会消耗大量的CPU资源,因此尽量一次性地调整好视图的布局,避免频繁地调整这些属性。文本计算、文本渲染
文本的宽、高计算会占用大量的CPU资源,并且是不可避免的,通常的文本显示控件(如:UILabel、UITextView等)其排版和绘制都是在主线程中进行的,当文本量较大时,会占用较大的CPU资源。优化的方法只有一个:自定义文本控件,用 TextKit 或最底层的 CoreText 对文本异步绘制。尽管这实现起来非常麻烦,但其带来的优势也非常大,CoreText 对象创建好后,能直接获取文本的宽高等信息,避免了多次计算(调整 UILabel 大小时算一遍、UILabel 绘制时内部再算一遍);CoreText 对象占用内存较少,可以缓存下来以备稍后多次渲染。图片解码
当你用 UIImage 或 CGImageSource 的那几个方法创建图片时,图片数据并不会立刻解码。图片设置到 UIImageView 或者 CALayer.contents 中去,并且 CALayer 被提交到 GPU 前,CGImage 中的数据才会得到解码,这一步是发生在主线程的,并且不可避免。可以参考的优化方法:在后台线程中将图片绘制到CGBitmapContext中,并直接从Bitmap中创建图片。图像绘制
这里通常是指用那些以 CG 开头的方法把图像绘制到画布中,然后从画布创建图片并显示的过程,如果对视图实现了-drawRect:方法,或者CALayerDelegate的-drawLayer:inContext:方法,那么在绘制任何东西之前都会产生一个巨大的性能开销。为了支持对图层内容的任意绘制,Core Animation必须创建一个内存中等大小的寄宿图片。然后一旦绘制结束之后,必须把图片数据通过IPC传到渲染服务器。在此基础上,Core Graphics绘制就会变得十分缓慢。由于CoreGraphic的方法通常是线程安全的,因此可以把绘制任务放到后台线程中进行,绘制完成后再在主线程中更新UI。
3、GPU参与的任务
纹理的渲染
所有的 Bitmap,包括图片、文本、栅格化的内容,最终都要由内存提交到显存,绑定为 GPU Texture。不论是提交到显存的过程,还是 GPU 调整和渲染 Texture 的过程,都要消耗不少 GPU 资源。当在较短时间显示大量图片时(比如 TableView 存在非常多的图片并且快速滑动时),CPU 占用率很低,GPU 占用非常高,界面仍然会掉帧。避免这种情况的方法只能是尽量减少在短时间内大量图片的显示,尽可能将多张图片合成为一张进行显示。当图片过大,超过 GPU 的最大纹理尺寸时,图片需要先由 CPU 进行预处理,这对 CPU 和 GPU 都会带来额外的资源消耗。视图的混合 (Composing)
当多个视图(或者说 CALayer)重叠在一起显示时,GPU 会首先把他们混合到一起。如果视图结构过于复杂,混合的过程也会消耗很多 GPU 资源。为了减轻这种情况的 GPU 消耗,应当尽量减少视图数量和层次,并在不透明的视图里标明 opaque 属性以避免无用的 Alpha 通道合成。当然,这也可以用上面的方法,把多个视图预先渲染为一张图片来显示。图形的生成
CALayer 的 border、圆角、阴影、遮罩(mask),CASharpLayer 的矢量图形显示,通常会触发离屏渲染(offscreen rendering),而离屏渲染通常发生在 GPU 中。当一个列表视图中出现大量圆角的 CALayer,并且快速滑动时,可以观察到 GPU 资源已经占满,而 CPU 资源消耗很少。这时界面仍然能正常滑动,但平均帧数会降到很低。为了避免这种情况,可以尝试开启 CALayer.shouldRasterize 属性,但这会把原本离屏渲染的操作转嫁到 CPU 上去。对于只需要圆角的某些场合,也可以用一张已经绘制好的圆角图片覆盖到原本视图上面来模拟相同的视觉效果。最彻底的解决办法,就是把需要显示的图形在后台线程绘制为图片,避免使用圆角、阴影、遮罩等属性。
4、RunLoop
前面说过尽量把非UI相关的操作放到后台线程中执行,但是如果遇到UI相关的操作怎么办呢?苹果规定UI相关的操作必须放到主线程中执行。我曾经尝试过将CALayer的renderInContext方法放到后台线程中并发执行,虽然使用了@autoreleasepool{},但是多次进出页面后,内存消耗始终有增无减,而且偶尔还会出现EXEC_BAD_ACCESS的异常。
那么对于这类只能在主线程中执行的耗时UI操作应该怎么优化呢?
当在操作 UI 时,比如改变了 Frame、更新了 UIView/CALayer 的层次时,或者手动调用了 UIView/CALayer 的 setNeedsLayout/setNeedsDisplay方法后,这个 UIView/CALayer 就被标记为待处理,并被提交到一个全局的容器去。
苹果注册了一个 Observer 监听 BeforeWaiting(即将进入休眠) 和 Exit (即将退出Loop) 事件,回调去执行一个很长的函数:_ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv()。这个函数里会遍历所有待处理的 UIView/CAlayer 以执行实际的绘制和调整,并更新 UI 界面。
在AppDelegate中的didFinishLaunchingWithOptions方法中,使用CFRunLoopGetCurrent()获取主线程的RunLoop可以得到如下输出(只截取相关部分,输出的内容中还可以看到有关AutoreleasePool的创建释放机制、用户事件的响应等,感兴趣的可以自己研究一下):
1 | <CFRunLoopObserver 0x6000001256e0 [0x10f578c80]>{valid = Yes, activities = 0xa0, repeats = Yes, order = 1999000, callout = _beforeCACommitHandler (0x10c33fe01), context = <CFRunLoopObserver context 0x7fc6d9402b30>} |
可以看到App启动后,UIApplicationMain函数创建了主线程RunLoop并在其中添加了一个优先级为2000000(order = 2000000)的
observer,该优先级低于常见的其他observer,该observer监听RunLoop的kCFRunLoopBeforeWaiting和kCFRunLoopExit事件(activities = 0xa0)。这样,当RunLoop 即将进入休眠(或者退出)时,关注该observer会得到通知,然后将通过CATransaction提交的中间状态合并到GPU中处理并显示到屏幕上。该机制能很好地保证CA的流畅度。
我们可以模拟Core Animation的这个机制,在合适的时机把异步、并发的操作放到主线程中执行,以保证尽量不阻塞主线程。
四、开始优化
Talk is cheap, show me the code!
1、异步计算并缓存布局
这一步比较简单,使用GCD异步队列实现即可
1 | dispatch_async(dispatch_get_global_queue(QOS_CLASS_DEFAULT, 0), ^{ |
2、减少视图层级、使用轻量级视图,异步绘制
之前的视图中每个座位用一个UIButton表示,对于100*100个座位就有1万个UIButton,视图数量过大。这里考虑以行为单位创建视图,并且每行使用Core Graphic框架异步绘制
1 | @interface RowLayer : CALayer |
3、RunLoop优化
对于较少的视图,获取其缩略图可以直接用snapshotViewAfterScreenUpdates方法,但是对于很大的视图,snapshotViewAfterScreenUpdates貌似不太好使。这里使用逐行截图,然后拼接的方法。
首先,创建RunLoopObserver和RunLoopSource并将其添加到主线程的RunLoop上
1 | -(CFRunLoopSourceRef)runLoopSource { |
将每行的绘制操作封装并添加到队列中,每当self.runLoopObserver被回调时,从队列中取出一个绘制任务并执行
1 | RenderBlock renderBlock = ^(__unsafe_unretained CALayer *layer, CGContextRef thumnailCtx, CGContextRef rowCtx) { |
五、优化前后性能对比
优化后能很好地支持1万个座位了,以下均为1万个座位时的性能对比
1、支持的座位数量
| 测试机型 | 优化前 | 优化后 |
|---|---|---|
| iPhone 5s | 5000个座位(正常显示) | 5000个座位(正常显示) |
| iPhone 5s | 10000个座位(页面空白) | 10000个座位(正常显示) |
优化后1万个座位可以正常显示了,由于后台最多只能创建1万个座位,更多的座位数目无法测试。经过优化后理论上可以支持10万+的座位数。
2、帧率
| 测试机型 | 优化前 | 优化后 |
|---|---|---|
| iPhone 5s | 40~45 | 55~60 |
3、内存
| 测试机型 | 优化前 | 优化后 |
|---|---|---|
| iPhone 5s | 230MB左右 | 120MB左右 |
优化前,重复进入、退出选座页面若干次后,App因内存消耗过大被系统kill;
优化后,重复上述操作若干次后,内存消耗比较稳定且没有出现闪退现象。
4、页面卡顿时间
| 测试机型 | 优化前 | 优化后 |
|---|---|---|
| iPhone 5s | 3s左右 | 0s |
优化前,进入选座页面后,数据加载完后要等待3s左右才能进行操作,在此期间App卡住且不响应任何用户操作;
优化后,进入选座页面后,数据加载完后可以立即响应用户操作,不存在卡顿时间。